Http(Hyper Text Transfer Protocol) without exaggeration is the most popular web protocol. It was developed in early 1991 with present needs in mind and allowed everyone to share and access the information through the internet using HTML(Hyper Text Markup Language).
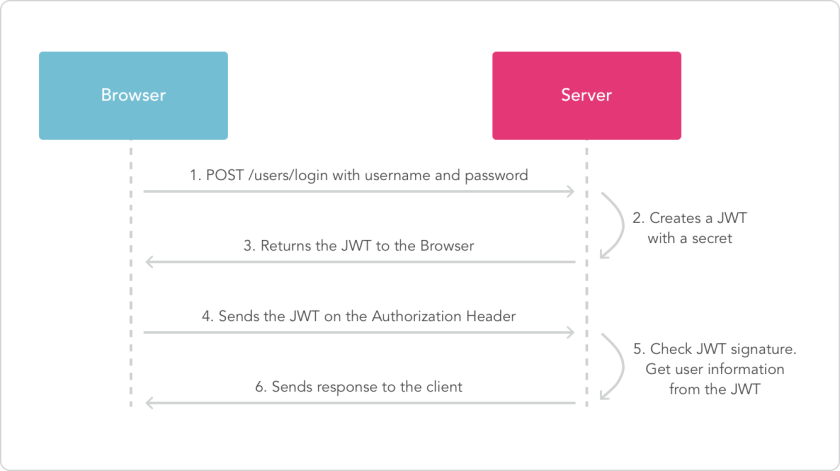
It’s a client-server protocol which means that resources should be stored on special kind of machines – servers, and users(clients) need to request this data from the server directly. The main actor of communication – resource. It’s identified by URI(Uniform Resource Identifier).
Http is stateless by design. It means that there’s no intermediate state between request-response pairs. Nevertheless, clients and servers can store information about the state in separately implemented mechanisms like cookies on client side and sessions on the server side.
Most of modern web programmers don’t work with HTTP directly. They use some third-party libraries and tools which provide abstraction, simplify development and increase quality. For example, Java programmers at most use Servlet API. This standard gives users already implemented HTTP-specific type system, for example HttpServletRequest, HttpServletResponse, HttpSession e.t.c.
Those programmers don’t know how HTTP works under the hood. So this article may be helpful for them. I’ll provide brief comparison of HTTP and it’s successor – HTTP 2.0.
So, as I said, the first version of HTTP(0.9) was developed in 1991.
In 1996 HTTP 1.0 was released.
1999 gives us HTTP 1.1, the most popular HTTP protocol for today. The most important new feature was a persistent connection between client and server.
There were no changes to the protocol about 15 years. But in 2015 new version of HTTP, 2.0, was standardized. This release has major implications on how we, developers should design and implement our HTTP applications. So I propose to look carefully into the protocol and describe new features that provided by it.
At first, let’s look at some statistics about HTTP 2.0 usage:
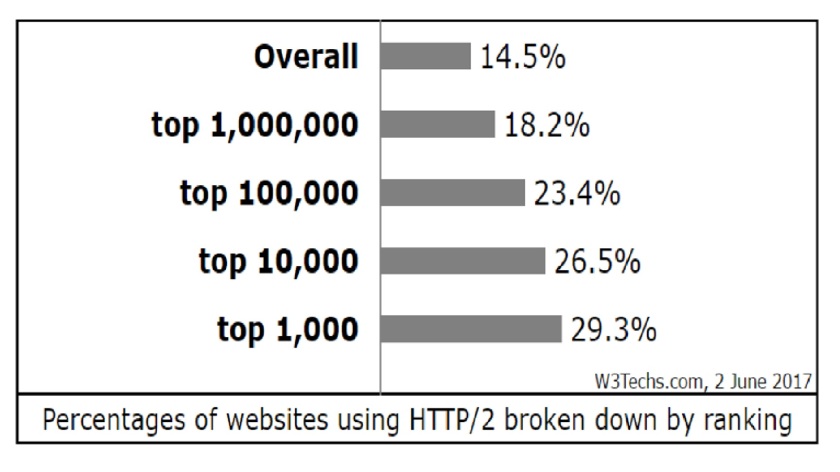
As you can see, it’s an overall trend to migrate from HTTP 1 to HTTP 2. So you need to learn in order to not to be overboard.
What’s new in HTTP 2.0?
Binary frames.
Unlike HTTP 1.1, HTTP 2 uses binary data for communication. It has an indisputable advantage: data is compressed and it will take less time to translate it through the network. Here’s an image which illustrates the difference in this aspect between HTTP 1.1 and HTTP 2.
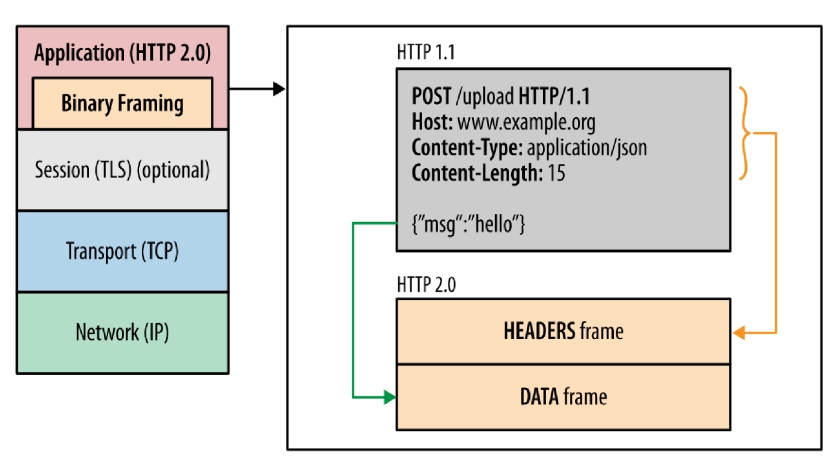
Because of binary frames, HTTP 2.0 is not back-compatible with HTTP 1.
Multiplexing.
In HTTP 1.1. for multiple parallel requests(for example, static resource loading), multiple TCP connections were used. The new binary mechanism provides the possibility to not open few TCP connections for related requests. It makes interaction more productive.
Headers compression.
There’s a huge optimisation for headers transfering. HTTP 2 sends all of them in hoffman-compressed form, besides that, for the same TCP connection headers should not be sent twice. Second time only index of the header will be send.
Server push.
This is a new possibility for server to response for the client request more than once. It changes request-response one-to-one mapping to one-to-many.
I’ve listed only few new features of HTTP 2.0 but as you can notice, even they change our notion of how to write programs.